
八爪鱼采集器最新版是一款十分好用的数据采集工具,它通过模拟人浏览网页的行为,可以快速将网页数据转化为结构化数据。八爪鱼采集器最新版为用户提供了网页抓取、多媒体保存、个性化规则定制等功能,全方位满足用户的使用需求。其界面简洁,操作简单,即使没有编程背景的用户也能轻松上手。
软件亮点
海量模板
内置300+主流网站采集模板,只需简单设置参数,即可获取网站公开数据。
智能采集
内置多种人工智能算法与自动化行为操作,轻松采集各种复杂网站场景。
0基础小白神器
无需学习爬虫编程技术,可视化采集流程设计,0基础小白也能轻松上手。简单3步即可获取网页数据。
强大的自定义采集
可实现全网99%以上的网页数据采集,支持文字、图片、文档、表格等文件采集下载。
高效稳定云采集
5000台云服务器,7*24高效稳定采集,API对接内部系统,日均可采集10亿+数据无错漏。

使用教程
创建采集任务
点击 “新建任务” 按钮,在弹出的对话框中选择 “自定义采集” 或 “智能模式” 等采集方式,输入任务名称和网址,点击 “保存” 按钮,创建一个新的数据采集任务。
进入任务配置页面,可以设置浏览器模拟、代理 IP、定时采集等参数。
设置采集规则
根据目标网站的结构和内容,制定相应的采集规则,如数据抽取、翻页、链接提取等。
使用八爪鱼采集器提供的可视化工具,如元素选择器、正则表达式等,对网页元素进行精确匹配和提取。
若网页存在翻页,可先建立翻页循环。例如,选中页面上的【下一页】按钮,在弹出的任务对话框中,选择高级选项中的【循环点击下一页】,软件会自动建立一个翻页循环。
对于当前页上的内容,可选中需要采集的元素,如图片等,单击后软件会自动弹出对话框,建立一个元素循环列表,抓取当前页面的所有相似元素。
选择元素循环列表中的元素,设置要抓取的内容及对应的字段名,如抓取图片的 URL 及图片标题名称等。
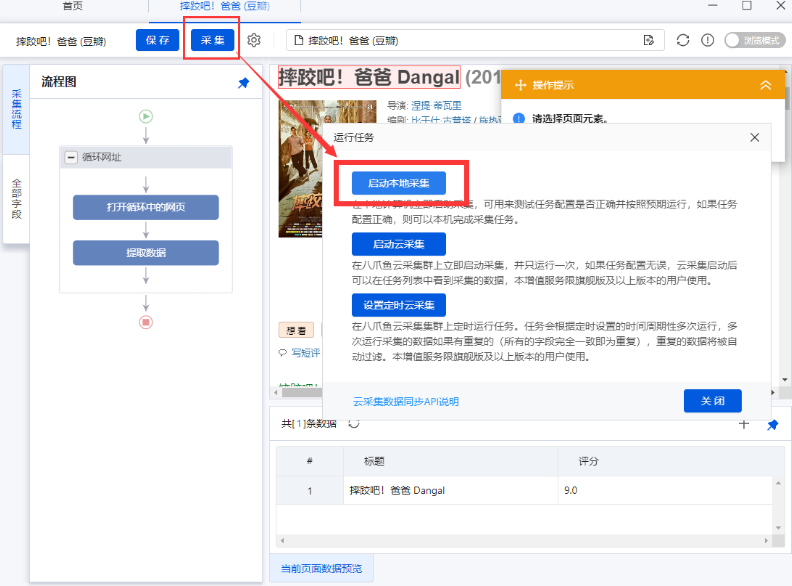
开始采集
检查采集流程图是否正确,确认能够采集到所需的数据。
点击右上角的采集按钮,在弹出的窗口中选择采集方式,如本地采集(普通模式),等待采集完成。
在采集过程中,可以随时点击停止或暂停按钮,控制采集的进度。
数据处理与导出
采集完成后,可以利用八爪鱼采集器的内置功能对数据进行处理,如自动识别并标记重复的数据项,通过设置过滤规则过滤无效数据,手动或自动纠正错误数据等。
点击导出数据,按需求选择导出所有数据或者去重数据,选择导出文件类型,如 Excel、CSV、JSON 等,并设置保存路径及文件名称,即可将数据导出到本地,方便后续的分析和使用。
安装方式
在纯净之家下载最新的安装包,根据提示安装即可。
常见问题
导出数据是否有上限?超过上限怎么办?
在八爪鱼的新套餐版本中(免费版、个人版、团队版、企业版),免费版有导出数据上限,每月5万条,个人版、团队版、企业版均没有数据导出上限。免费版超过数据导出上限需要升级套餐,
怎么导出excel表格?
采集到数据后,选择导出数据,然后选择导出excel表格。
采集好的任务数据存在什么地方?
本地采集的数据是存储在您的本地电脑的缓存里的,在清理软件缓存的时候也会一并清理;云采集的数据是存储在云端服务器上,云端数据最多可以保存3个月,本地采集和云采集的数据都可以在软件的任务列表中点击查看。
导出到远程数据库Mysql,在导出向导中看不到表字段?
当数据导出到远程Mysql时,不是localhost上的数据库而是远程的,可以连接数据库看到表名,但在导出向导中看不到表字段,无法建立目标数据字段映射,是因为对远程的user没有grant select权限。