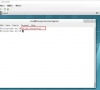
Kali Linux如何修改默认whisker菜单图标?
在使用Kali Linux系统的时候,想要更换默认的whisker菜单图标,要怎么修改呢?下面我们就来看看详细的教程吧,需要的朋友可以参考下。
更新日期:2021-10-15
来源:纯净之家
Kali Linux如何修改默认whisker菜单图标?
在使用Kali Linux系统的时候,想要更换默认的whisker菜单图标,要怎么修改呢?下面我们就来看看详细的教程吧,需要的朋友可以参考下。
Linux系统声音不如windows大?下面这样做轻松恢复Linux系统音量
经常有一些用户,在Windows系统上安装linux系统后会发现后者的声音竟然更小,但是自己也不知道是怎么回事,还以为是电脑坏了,最后只能不了了之或者找错原因还破坏了其它功能,解决linux系统声音小的方法并不难,今天小编要分享的正是如何修复linux系统比windows系统声
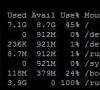
Linux系统怎么查看电脑的磁盘空间?
Linux系统怎么查看电脑的磁盘空间?Linux作为一款开源的操作系统,许多用户都在使用这款系统,而这款系统的操作方法和Windows完全不一样,下面小编就带着大家一起来看看怎么操作吧! 操作方法: Linux 查看磁盘空间可以使用 df 和 du 命令。 df df 以磁盘分
怎么远程登录Linux CentOS系统?远程登录Linux CentOS系统方法教学
怎么远程登录Linux CentOS系统?许多Linux系统用户都知道Linux最常用的就是作为服务器端放在机房中,而我们用户不可能实时待在机房中,那么有没有什么方法远程操控Linux系统呢?下面小编就带着大家一起看一下吧! 远程登录Linux CentOS系统方法教学 CentOS系

怎么制作Cdlinux启动U盘?Cdlinux U盘启动制作教程
U盘是一件非常好用的存储工具,体积小巧但是存储容量大,还可以用来重装系统,深受人们的喜爱。CDlinux是有极其鲜明特色的一种小型GNU/Linux发行版软件,我们可以使用它进行系统维护或者将它装进U盘变成一个可移动的操作系统。下面我带来了制作CDlinux U盘启
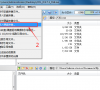
Linux如何查找shadow文件进入?这样几步轻松搞定!
在Linux系统中,用来存储用户的密码信息的文件一般又叫“影子文件”(shadow文件),最近小编收到很多小白反馈,自己在操作linux系统时不知道怎么找到这些影子文件,究竟要怎么做才能在linux系统中找到影子文件呢?今天小编就为大家分享一下Linux查找shadow文

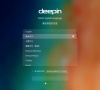
Deepin Linux怎么安装?Deepin Linux安装步骤简述
Deepin是由武汉深之度科技有限公司开发的Linux发行版,适用于笔记本、桌面计算机和一体机,且几乎包含了用户所需全部软件。那么,Deepin Linux该怎么安装呢?下面小编就来简单介绍一下Deepin Linux安装的步骤,小伙伴们可不要错过了。
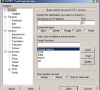
机房太远不想去?Linux远程登录服务器的方法
Linux作为开源系统,不少厂商用它来制作服务器系统,而服务器处于机房之中,作为企业的重要核心,要进去机房需要多层步骤,麻烦费时。那么不进机房可以操作Linux服务器么?答案是可以的,下面小编就跟大家讲解一下Linux服务器远程登录的方法。
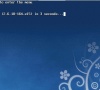
Linux忘记密码怎么办?root密码找回方法
生活处处要用到密码,为了不让密码重复,往往会根据需求设置不同的密码,这样就会造成密码众多容易遗忘的后遗症。那么Linux的root密码忘记了怎么办?要如何找回密码?下面小编就跟大家分享下Linux密码找回的方法。
Linux有什么优缺点?Linux优缺点简析
Linux系统作为一个开源性的操作系统,受到不少程序员的青睐,衍生出各种不同需要的版本,可以根据自身需要进行修改设置,比起微软更受企业欢迎,大部分网站的主流系统都是它。那么Linux有什么优缺点?下面小编就和大家探讨一下。

Windows服务器和Linux服务器选哪个好?Windows服务器和Linux服务器区别
服务器一般是许多企业必须拥有的,但是目前市面上的服务器主要分为Windows服务器和Linux服务器,不少用户在使用的时候不知道应该选哪一个,遇到这种情况要怎么办呢?下面小编就带着大家一起看看两者的区别,方便用户选择。 Windows系统服务器具有那些不同呢

Linux新手入门:PS命令查看正在运行的进程
Linux作为开源系统,里面有着大量命令需要了解和使用,同样的命令在不同系统中的使用方法各不相同,例如本次要介绍的PS命令,那么什么是PS命令?要如何使用PS命令?下面小编就跟大家详细讲解Linux PS命令。

Xshell怎么远程桌面连接Linux系统?
相信在平时的工作中,因为某些需要,很多Windows系统用户都有远程桌面连接过其它计算机,在Windows系统中远程桌面连接是很简单的,但在Linux系统中就没那么容易了。那么,Linux系统要怎么远程桌面呢?下面,我们就一起往下看看Xshell远程桌面连接Linux系统的方法。
鸿蒙系统基于linux吗?鸿蒙系统是否基于linux详细介绍
鸿蒙系统是华为自主研制的操作系统,很多的小伙伴不了解不知道它的系统是不是基于linux,这里小编为大家带来了鸿蒙系统是否基于linux详细介绍,有需要的快来看看吧!

命令太长输入烦?这就教你linux里用alias创建命令别名的方法
许多用户还不知道什么是alias命令,其实这是在Linux系统中的一个工具,能够让我们把一些经常使用的很长的命令设置成别的名字,当下次再使用的时候,直接输入你设置的名字即可,具体操作是怎么样的呢?下面就看看小编分享的linux系统用alias创建命令别名的方法